
What makes a design good?
Designers usually talk about the usability of the product or interface, how well it performs, the intuition of its layout, and maybe even its performance towards some target or goal (like clicks!). However, designers shouldn’t focus just on these features alone. The propensity for a designed product or system to fail is a very important consideration for designers.
This is often not thought of when discussing design and user experience. Those efforts focus on what the normal circumstances of use are, and then try to optimize the experience and performance under those conditions. These conditions are sometimes referred to as the optimal design domain (ODD).
When the focus is on failures, we typically consider the circumstances and behaviors outside of the ODD. In fact, this is one of the chief ways to evaluate good design. By looking at how often a product of system fails and to what severity the result of the failure is says a lot about the goodness of the design. Looking outside the ODD, to consider non-routine circumstances, incorrect usage behavior, and design risks, can help create a more reliable and resilient design.
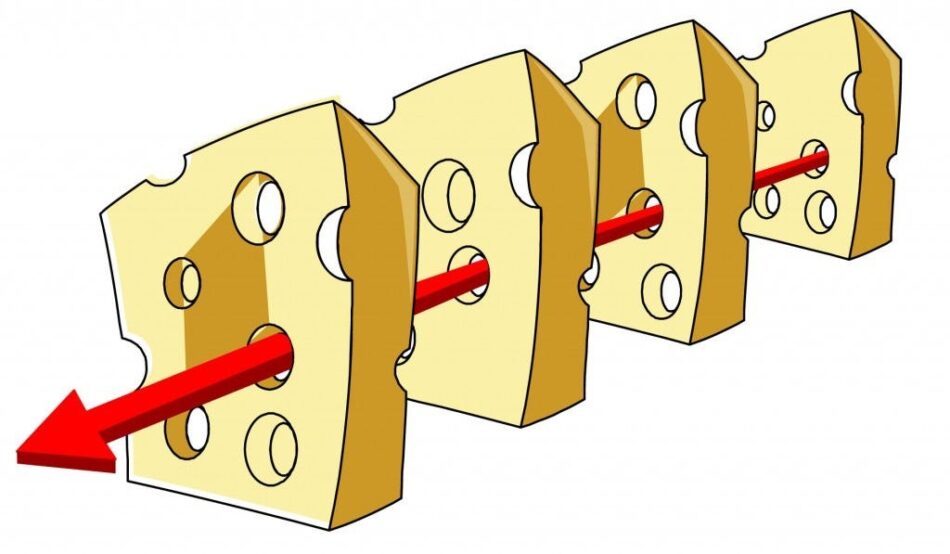
Swiss Cheese Model. When things go wrong.
Source: Reason, 1997
When things go wrong we search for a causal explanation. And since things usually don’t go wrong, when they do the causal explanation usually focuses on the behavior of the users. More elegant explanations may also focus on system dynamics like and “states” of the system, but the focus follows intuition and remains on the events immediately preceding the failure. These are called active failures. Active failures are are exactly what we expect them to be; the errors, behaviors, settings, and choices that immediately cause a failure.
However, this is not the only immediate cause of failure. There are other factors that lie in wait, dormant, but with the potential to reek havoc. These are called latent failures. Unlike the active failures, the consist of decisions and choices from managers, engineers, and designers. Latent failures occur months, sometimes years, before hand as the design choices were made and implemented into the system.
In 2000, Human Performance expert, and psychologist James Reason introduced a framework for understanding system failures and to demonstrate the impact of latent errors. He called it the Swiss Cheese Model. The model is relatively straightforward. For any system, there are many layers that can stop a failure from occurring. These layers include management decisions, design, machine performance, user behavior, protocols, and safety features.
Source: https://www.pressesdesmines.com/
In short, the Swiss Cheese Model is an end to end vignette of every factor that could possible contribute to an error. If any layer performs correctly, the failure is prevented from propagating. However, in the event that all the layers are penetrated, then the system failure is created.
As an example of the application of this model, consider the HMS titanic. The tragedy is not just the result of not seeing an iceberg, but also includes management decisions such as the speed of the ship, the route taken, the time of year, and of course the material failure of the watertight compartments of the ship. Had any one of these things not been present, the tragedy would likely not have occurred.
The Swiss Cheese Model has important implications for designers. By the logic of the model, good design can prevent all failures from occurring. If that’s not 100% true in practice, it’s certainly close. A good design can stymie a potential failure from ever propagating through an organiation.
Resident Pathogens
However, it is unlikely that a designer will be able to create a design that is so robust that it prevents any and all failures, especially those caused by circumstances outside of the ODD. How then should designers think about design for the prevention of failures and latent errors? One way is through something called the resident pathogen metaphor.
Source: News-Medical.Net
A resident pathogen is a medical idea that explains the presence of about diseases in an organism. Simply stated, no one pathogen (bacteria, cancer cell, carcinogen, virus) causes a disease, but as the number of pathogens increases within the organism, so does the probability of having the disease. James Reason offers this metaphor as a constructive way of thinking about latent failures and design errors. Replace the pathogen with design defects and the organism with an organization. The better the design, the less likely a failure will result.
Reason explains:
“Latent failures are analogous to ‘resident pathogens’ within the human body, which combine with external factors (stress, toxic agencies, etc.). to bring about disease. Like cancers and cardiovascular disorders, accidents in complex, defended systems do not arise from single causes. They occur through the unforeseen (and often unforeseeable) concatenation of several distinct factors, each one necessary but singly insufficient to cause the catastrophic breakdown.”
Using this metaphor as a guiding light, we can say learn a few things about the causes, impact, behavior and propagation latent failures.
First, and most obvious, the likelihood of issues within a system increases as the number of pathogens (design defects) increases.
Second, The more complex, coupled, and opaque a system is, the greater number of pathogens (design defects). This is true for several reasons. consider a company with siloed and secretive projects, like defense contractors. The designer herself may not have all the relevant details to create the best design. Next, complexity cannot be controlled, only managed. If a system is excessively complex, there are many interactions within the system that a unknown. Their effects are likewise, unknown. Lastly, excessive opaqueness and complexity are not great outputs of design. If a designer creates such an output, it is likely the case that many design considerations have slipped through the cracks.
Third, activities that are more effective and profitable aim at the proactive identification and neutralization of these latent failures rather than ongoing prevention and detection of active failures. It’s better to prevent cancer than treat it.
Fourth, it is impossible to see and address all possible triggers of failures. Though pathogenic risks may be assessed through system knowledge.
Poor remedies
In light of the existence of design defects and impending failures, what should be done? There are many options available to address the challenges. However, several of these options seem like good ideas on the surface, but which actually have little effect on the system and in some cases the exact opposite of the intended effect.
The first remedy is user and operator training. This remedy is probably familiar to all readers. Usually, training is conducted as part of the user initiation process. New users and operators are taught how a particular system functions. These types of trainings may be carried out by a trained facilitator, a peer, or a subject matter expert. Each have their own pros and cons, but what’s more important here is that the focus of the training is almost always the same — the normal use and operation of the system. In short, training, especially when coupled with an introduction of the system focuses to train the operator on how to choose behaviors that keep the system within the ODD.
This approach to mitigating the risk of latent failures is clearly faulty. As we’ve already noted in the Swiss Cheese Model, the impact of latent errors are most likely to occur exactly when the system is operating outside of the ODD. While it’s important to try to ensure normal operation as much as possible, it does little to address the risk of latent errors when the inevitably occur.
Another technique which has prima facie merit is to detect and address design errors. This can have some impact, especially if it is done in a systematic way, like using a Failure Modes and Effects Analysis (FMEA) tool. The benefits of these tools are that they allow you to think about the way things could possibly go wrong and then determine effects and causes, forcing you to think more creatively. Nevertheless, it still remains difficult to think outside of the ODD paradigm. While a completed FMEA may significantly reduce the number of resident pathogens within a system, it still does nothing to improve the resilience, response and recovery in the event of failure.
Source: Boeing.com/
Why not just add a bunch of extra safe guards? If the issues of latent failures occur when the system is operating abnormally, let’s just add restrictions so that it is impossible to operate in these scenarios. This approach seems logical, but actually violates many of the principles noted above. whenever we create systems that are complex, opaque, and the mediate the relationship between operation and result, we are actually adding more pathogens to the system. Consider an example. The 737 MAX was a poorly designed aircraft. Larger engines were added onto an existing design of a fuselage to save time and money in the development and manufacture of the aircraft. To prevent issues of stalling and to keep the 737 MAX within the ODD a safeguard, the Maneuvering Characteristics Augmentation System (MCAS) software, was installed to prevent the nose from rising too high too fast. This is well known. What’s not well known is that additional safeguards that deactivate the MCAS including changing the angle of attack, or pulling the fuse of the MCAS. These safeguards were what emboldened Boeing to move forward with a poor design. In fact it was the MCAS safeguard itself which end up causing the two Boeing 737 Max Crashes (Lion Air Flight 610 and Ethiopian Airlines Flight 302), which killed 346 in total. Bad design is actually worsened by creating safeguards.
Good remedies
Despite the common missteps of addressing latent failures, there are several remedies that can be offered to effectively stamp out their risks.
Situation Based Training. Unlike traditional training which focuses on teaching users how to maintain the system to achieve a particular output, situation based training has a very different purpose. Its aim is to provide opportunities for operators to work through unfamiliar scenarios and crisis situations. Airline pilots are great examples of this discipline. In order to maintain their license, they must record several hours of flight simulator training. This simulation training is not just routine, but focuses on handling difficult scenarios like engine failures and cabin depressurization. These situation based trainings aim to reinforce rules and patterns of thinking that can aid in choosing the correct behavior. I’ve written much more about the different levels of cognition and problem solving previously on UX Collective.
Source: Airforcetimes.com/
Simulation. Similar to situation based training, simulation provides opportunities to become more acquainted with fringe situations. Also like situation based training, simulations can be constructed in such a way that allows particular, infrequent circumstances to be evaluated extensively, sometimes with several thousands of trials. Simulation also holds value in that it offers exploration of system dynamics (Of which I’ve written about here) that can eliminate likely latent design flaws.
Simulation can take many forms. Monte Carlo Simulations and Discrete Event Simulations are two of the most popular for modelling systems. However, for extensively complex systems, agent-based simulations can reveal even greater insights through the combination of situation based training and simulation. Conducttr, a crisis exercise simulation platform is an excellent example. By using a wide network of actors with different levels of controls, objectives, and boundaries, governments and private organizations can simulate crisis scenarios, revealing potential vulnerabilities.
Error Handling. Another expert way of handling latent errors is to plan for them. Software design is a prominent user of this technique. With so many lines, so much complexity, and so many systems relying on the code, of course something will go wrong. Consider what Geek for Geeks says about this simple, common practice.
Source: Freshsparks.com/Error handling in Programming is a fundamental aspect of programming that addresses the inevitable challenges associated with unexpected issues during code execution.
The best practice of software engineers is to anticipate errors and create rules to handle the errors when they do occur.
Adaptive Situational Modes (ASMs). ASMs are are procedures that are used to prevent errors from occurring when situations escalate towards the fringe and outside of the ODD. The procedures are best explained through example.
Air Traffic Controllers (ATCs) have some of the most critical jobs in the world. They are responsible for directing air traffic at different altitudes and on the ground, as well as maintaining schedules and above all safety. even one mistake can mean the lives of several hundred people. One way they manage the safety amidst varying environmental conditions, traffic, and fatigue is through ASMs. ATCs have pre-defined modes of operation for circumstances that are hazardous or affords errors more readily.
During periods of high traffic volume, controllers may prioritize efficient spacing of the aircraft, and adjust normal separation standards. In adverse weather, ATCs may shift their focus on rerouting flights and managing holding patterns, an alternative approaches rather than ground traffic. If system or mechanical disruptions occur, ATCs have adaptive norms to switch and rely on alternative communication methods to ensure safety.
There are several more examples within Air Traffic Control and other critical jobs and industries also use ASMs. A chief takeaway of ASMs is that the belief that failure is possible and even likely. They switch from normal modes of operation to special modes that don’t take the design specifications and parameters of the existing system for granted.
Source: KLM.nl/
As you may have noticed, good remedies rely almost entirely on the users and operators of the system as the last line of defense. In light of the Swiss Cheese Model, this makes sense. The latent errors cannot be detected and prevented. The system is in a state that is different than the ODD, the only thing left is for to wait for the active failure or correct behavior of the operator.
Latent Failures — Legacy and future in design
“A point has been reached in the development of technology where the greatest dangers stem not so much from the breakdown of a major component or from isolated operator errors, as from the insidious accumulation of delayed-action human failures occurring primarily within the organizational and managerial sectors.”
Reason makes this claim in 1990. If his point was true then, it’s certainly true now. Yet how often have our efforts been directed towards solving, let alone acknowledging this challenge. The best remedies of situation based training, simulation and adaptive situational modes are still not widely used. Even more absurd, is that there seems no real reason why they shouldn’t be.
Latent errors are not just the failures of designers and engineers. They also include, among other things, management decisions, cultural norms, and even customer expectations. Nevertheless, designers play a vital role in propagating potential failures throughout a system. The chief way designers can reduce latent errors is through making simple, non-complex connections and relationships between systems. They can also bolster transparency in systems, especially between the actions of the end user and the results.
Designers should also be aware of ways they can work cross-functionally to mitigate the impact and risk of latent errors. They out to advise end users, engineers, and stakeholders of some of the best practices in this area, while also warning them of the poor remedies and paradoxes discussed above.
Since the time of Reason’s quote, we’ve seen the technological revolutions of the internet and smartphones. We now stand on another cusp of generative artificial intelligence, autonomous vehicles, and green energy. Latent failures will continue to propagate, even in greater number as our technologies become more complex and opaque. We ought to strive to make systems that reduce the inherent resident pathogens, and work in multidisciplinary fashion to prepare ourselves for the impact of future latent failures.
Bad design is like a virus: design defects and latent failures was originally published in UX Collective on Medium, where people are continuing the conversation by highlighting and responding to this story.



